> For the complete documentation index, see [llms.txt](https://sysnet4admin.gitbook.io/cncf/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://sysnet4admin.gitbook.io/cncf/blog-and-news-ko/blog/member/opentelemetry-kafka.md).
# OpenTelemetry를 이용한 Kafka 기반의 비동기 워크플로우 테스트(2023.04.04)
> **한줄 요약:** 오픈텔레메트리(OpenTelemetry)를 사용해서 카프카(Kafka)의 비동기 시스템을 효과적으로 확장하는 방법에 대해서 설명하고 있습니다.
>
> **관련 프로젝트:** \
> \- \
> \-
{% hint style="info" %}
이 문서는 기계 번역 후에 일부 내용만 다듬었으므로, 보다 정확한 이해를 위해서는 원문을 보는 것이 좋습니다.
{% endhint %}
2023년 4월 4일에 게시됨 ([Link](https://www.cncf.io/blog/2023/04/04/testing-kafka-based-asynchronous-workflows-using-opentelemetry/))
Arjun Iyer와 Scott Cotton이 [Signadot 블로그](https://www.signadot.com/blog/testing-kafka-based-asynchronous-workflows-using-opentelemetry/)에 게재한 게스트 게시물입니다.
## 소개
비동기 아키텍처는 서비스를 분리하고 시스템의 확장성과 안정성을 향상시키기 때문에 클라우드 네이티브 애플리케이션에서 흔히 사용됩니다. 메시지 큐는 비동기 아키텍처의 기초를 형성하며, Kafka, RabbitMQ와 같은 오픈 소스 도구부터 Google Cloud Pub/Sub, AWS SQS와 같은 관리형 시스템에 이르기까지 무수히 많은 옵션 중에서 하나를 선택할 수 있습니다. 메시지 큐에 사용할 수 있는 다양한 옵션 중에서 Apache Kafka는 높은 처리량과 짧은 지연 시간으로 인해 클라우드 네이티브 애플리케이션에서 널리 사용되고 있습니다. Kafka의 분산 아키텍처, 내결함성, 확장성은 복원력과 응답성이 뛰어난 비동기 아키텍처를 구축하는 데 이상적인 선택입니다.
### Kafka 기반 비동기 워크플로우 테스트
Kafka는 분산 시스템이기 때문에 테스트 환경을 설정하려면 브로커, 프로듀서, 컨슈머와 같은 여러 구성 요소를 설정해야 합니다. 보안, 복제, 파티셔닝 등을 고려하여 올바르게 구성해야 합니다. 또한, 특히 다양한 프로그래밍 언어와 프레임워크를 다루는 경우, Kafka에 퍼블리시하고 소비하는 서비스를 설정하는 데 많은 시간이 소요될 수 있습니다. 따라서 엔드투엔드 플로우를 격리된 방식으로 테스트하기 위해 Kafka를 포함하는 환경을 설정하는 것은 중요한 결정이 필요하게 됩니다.
*이러한 맥락에서 테넌트를 테스트 시나리오를 독립적으로 실행해야 하는 액터로 정의합니다.*
다음은 리소스 격리 및 비용 측면에서 각각 고유한 장점과 장단점이 있는 Kafka를 포함하는 엔드투엔드 플로우를 테스트하기 위한 세 가지 접근 방식입니다.
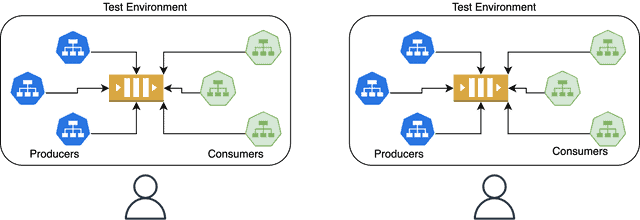
### 1. Kafka 클러스터 격리
테넌트 간에 완전한 격리를 원하는 경우, 모든 프로듀서와 컨슈머를 포함하여 각 테넌트에 대해 새로운 Kafka 클러스터를 생성하도록 선택할 수 있습니다. 그러나 이 접근 방식은 특히 많은 서비스와 함께 리소스 집약적인 Kafka 클러스터가 있는 경우 관리가 어려울 수 있습니다. 메인 브랜치에 병합된 변경 사항으로 각 환경을 최신 상태로 유지하는 자동화가 없다면, 이러한 환경은 빠르게 구식이 될 수 있으며 유지 관리에 상당한 노력이 필요할 수 있습니다.
**장점:**
* 환경 간 높은 격리 수준
**고려 사항:**
* 각 테넌트마다 전체 인프라를 복제해야 하므로 높은 비용 발생
* 여러 독립적인 환경의 복잡한 관리 오버헤드
* 각 환경의 모든 서비스를 지속적으로 업데이트하기 위한 자동화 필요
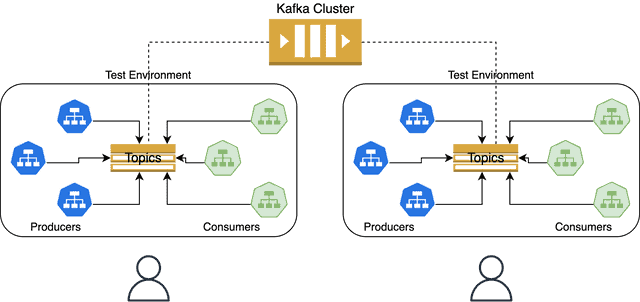
### 2. Kafka 토픽
격리 또 다른 옵션은 모든 테넌트에 대해 단일 Kafka 클러스터를 사용하고 각 테넌트에 대해 필요에 따라 새로운 임시 토픽을 생성하는 것입니다. 엔드투엔드 플로우를 테스트하려면 여전히 모든 프로듀서와 컨슈머를 스핀업하고 새로 프로비저닝된 토픽에 연결하도록 재구성해야 합니다. 이 옵션을 사용하면 이전 접근 방식에 비해 비용을 절감할 수 있지만, 새 토픽마다 이러한 서비스를 복제하고 재구성해야 하므로 Kafka를 사용하는 프로듀서와 컨슈머의 집합이 복잡한 경우에는 실용적이지 않을 수 있습니다.
**장점:**
* 여러 환경에서 Kafka 클러스터를 공유하여 비용 절감 실현
**고려 사항:**
* 각 테스트 환경에 대한 Kafka 토픽 설정 및 해체에 대한 자동화 설정의 필요성
* 각 환경마다 모든 서비스를 복제해야 하므로 운영이 복잡해질 수 있습니다.
* 새로 생성된 토픽에 연결하기 위해 모든 서비스를 재구성해야 하므로 오류가 발생하기 쉽습니다.
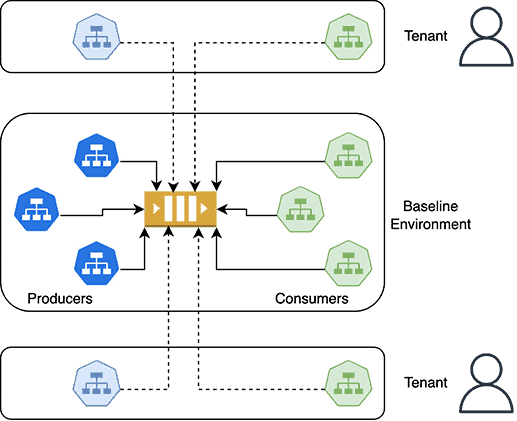
### 3. Kafka 메시지 격리
이 접근 방식에서는 Kafka와 프로듀서 및 컨슈머를 포함한 모든 서비스를 포함하는 "기준" 환경을 설정합니다. 이 기준선은 선택한 CI/CD 도구를 사용하여 지속적으로 업데이트되는 사전 프로덕션 환경일 수 있습니다. 모든 테넌트가 이 기준선을 공유합니다. 각 테넌트는 "테스트 중" 서비스 집합에 대한 매핑을 가지고 있습니다. 테넌트를 서로 격리하기 위해 요청 및 메시지의 동적 라우팅을 활용합니다. OpenTelemetry를 사용하여 헤더에 태그를 지정하고 서비스 및 Kafka를 통해 전파합니다. 그런 다음 요청과 메시지는 이러한 헤더 값에 따라 특정 서비스로 동적으로 라우팅됩니다.
**장점:**
* 테스트 환경마다 인프라를 설치/해체할 필요가 없습니다.
* 가장 비용 효율적인 모델, 특히 복잡한 Kafka 설정과 많은 서비스가 있을 때 유용합니다.
* 각 환경마다 최소한의 서비스만 실행되므로 운영 오버헤드가 가장 낮습니다.
* 기존 CI/CD 파이프라인을 기반으로 기준선이 지속적으로 업데이트되므로 오래된 환경 문제 제거
**고려 사항:**
* OpenTelemetry를 사용하여 서비스를 계측하려면 약간의 노력이 필요합니다.
* Kafka에서 선택적으로 소비하기 위해 Kafka 컨슈머를 수정해야 합니다.
* 인프라 수준 격리가 필요한 경우 최선의 선택이 아닐 수 있음
비동기 흐름에 대해 비용 효율적으로 테스트를 확장하기 위한 최적의 접근 방식은 위의 옵션 3입니다. 이에 대해서는 이 문서의 나머지 부분에서 자세히 설명합니다.
## 메시지 격리 기반 테스트 구현하기
이 시스템에서는 테넌트에게 함께 테스트해야 하는 특정 "테스트 중" 서비스 버전에 대한 매핑이 포함된 고유한 테넌트 ID가 할당됩니다. 요청이나 메시지가 전송될 때 마다 테넌트ID로 태그가 지정되고 매핑에 따라 특정 서비스 버전으로 동적으로 라우팅됩니다.
테넌트ID는 동기 및 비동기 서비스 간 통신 중에 라우팅 결정을 내리는 데 사용되므로 서비스 호출에 걸쳐 전파해야 합니다. 동기 호출의 경우 http 또는 gRPC 헤더를 사용하여 전파할 수 있습니다. 다음으로, Kafka와 같은 비동기 시스템에서 이 작업이 어떻게 수행되는지 살펴봅시다.
### Kafka를 통해 tenantID 전파하기
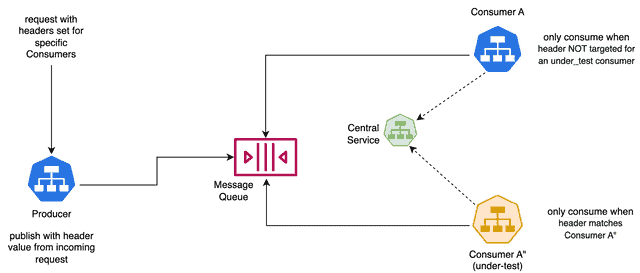
Kafka 프로듀서를 사용하여 메시지를 게시할 때는 메시지 헤더에 메시지의 대상 테넌트를 식별하는 tenantID를 포함시켜야 합니다. 일반적으로 이 테넌트 ID는 수신 요청이나 메시지에서 얻습니다. 동일한 주제에 대해 동일한 카프카 브로커에 게시하는 여러 버전의 프로듀서를 가질 수 있다는 점에 유의하세요. 각 메시지는 tenantID 헤더 값을 통해 라우팅 정보를 전달합니다.
### Kafka 컨슈머에게 메시지 라우팅하기
동일한 카프카 브로커를 공유하는 여러 카프카 컨슈머가 있는 경우, 각 컨슈머가 자신에게 의도된 메시지만 소비하도록 하는 것이 중요합니다. 이러한 메시지의 선택적 필터링은 중앙 서비스에서 테넌트 ID와 서비스 세트의 매핑을 검색하여 수행됩니다. 이를 위해서는 아래 의사 코드에 표시된 것처럼 Kafka 컨슈머에게 로직이 구현되어 있어야 합니다.
```
//fetch mappings of sandboxIDs <=> services
svc_mapping = call_central_service_to_get_svc_mapping()
//look over msgs and filter out the messages not intended for this svc
for each msg from Kafka:
sandboxID = get_sandbox_id (msg)
if (svc_mapping[sandboxID] includes _this_ service)
process msg
else
skip msg
```
토픽의 모든 메시지에 액세스하려면 각 카프카 컨슈머가 새 컨슈머 그룹의 일부로 카프카에 연결해야 합니다. 단일 카프카 인스턴스를 안전하게 공유하고 각각에 대해 의도된 메시지를 소비하는 데 협력하는 여러 버전의 컨슈머를 가질 수 있습니다.
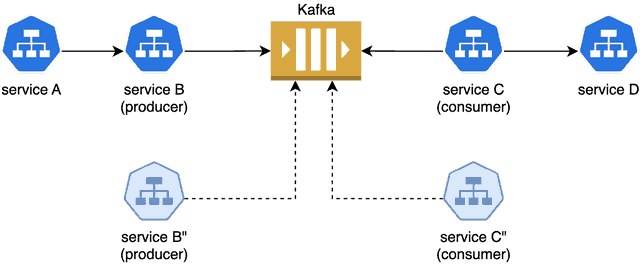
아래 다이어그램은 이 아키텍처를 보여줍니다:
## 컨텍스트 전파를 위해 OpenTelemetry 사용
테넌트 ID가 동기 요청과 비동기 메시지를 통해 전파되도록 하려면 OpenTelemetry(OTel)를 사용할 수 있습니다. OTel은 컨텍스트 전파를 지원하는 오픈 소스 통합 가시성 프레임워크로, 서비스 경계를 넘어 컨텍스트를 전파할 수 있습니다. OTel은 Baggage 형태의 사용자 정의 키-값 쌍을 포함하여 컨텍스트 전파를 위한 프레임워크를 계측하는 다양한 언어로 된 라이브러리를 제공합니다. 이를 통해 카프카를 비롯한 동기식 호출과 비동기식 메시지 전반에 걸쳐 테넌트 ID를 전파할 수 있는 편리한 메커니즘을 제공합니다. 또한 OTel은 애플리케이션 코드를 변경하지 않고도 컨텍스트 전파를 활성화하는 데 사용할 수 있는 Java, Node.js, Python과 같은 동적 언어에 대한 자동 계측을 제공합니다.
Kafka 프로듀서와 컨슈머가 Kafka를 통해 컨텍스트를 전파할 수 있도록 계측하려면 OTel 설명서에 제공된 구체적인 예제를 참조하면 됩니다. 이 예제에서는 퍼블리셔에서 Kafka를 통해 컨슈머에게 테넌트 ID를 전파하는 방법을 보여줍니다.
## 모든 것 종합하기
서비스 A, B, C, D와 Kafka를 기준으로 예시를 들어 보겠습니다. 새로운 버전의 서비스 B"와 C"로 엔드투엔드 플로우를 테스트하고자 합니다. 테넌트와 매핑을 관리하는 중앙 서비스가 있고, 모든 서비스에 테넌트 ID를 전파하기 위한 OTel 계측이 있다고 가정합니다. 테넌트를 설정하여 변경 사항을 엔드투엔드 테스트하는 방법은 다음과 같습니다:
1. B" 및 C"를 빌드 및 배포하고 이를 고유한 tenantID=123을 가진 테넌트와 연결합니다. tenantID의 메타데이터와 B" 및 C"에 대한 매핑은 중앙 서비스에 저장됩니다.
2. C"는 새로운 컨슈머 그룹의 일부로 Kafka에 연결하여 C가 수신하는 모든 메시지의 사본을 수신합니다.
3. tenantID 헤더 값을 "123"으로 설정하여 A에 HTTP 요청을 보냅니다. 이 요청은 tenantID=123 ⇒ (B", C")의 매핑에 따라 B"로 라우팅됩니다. 이 라우팅의 구체적인 메커니즘은 해당 서비스가 실행되는 인프라에 따라 달라집니다. 예를 들어, 쿠버네티스에서 실행되는 경우 서비스 메시 또는 사이드카가 사용될 수 있습니다.
4. B"는 헤더에 tenantID=123이 포함된 메시지를 Kafka에 게시합니다. 컨슈머 C와 C" 모두 이 메시지를 수신하지만 C는 메시지를 삭제하고 C"는 처리합니다.
5. C와 C" 모두 중앙 서비스에서 매핑을 가져와서 이 필터링을 기반으로 합니다.
6. C"는 tenantID=123을 http 헤더로 전달하여 D에 동기 호출을 합니다.
7. Kafka 또는 변경되지 않은 다른 서비스(예: A와 D)를 다시 배포할 필요 없이 전체 흐름 A → B" → Kafka → C" → D를 엔드투엔드로 테스트하세요.
8. 테스트가 끝나면 테넌트를 삭제하세요.
위의 예는 하나의 테넌트에 대한 엔드투엔드 테스트 시나리오를 보여줍니다. 이러한 시스템은 인프라를 복제하지 않고도 많은 수의 동시 테넌트를 지원할 수 있습니다. 다음으로 이러한 멀티테넌트 시스템을 구현할 때 고려해야 할 몇 가지 추가 사항을 살펴보겠습니다.
## 추가 고려
사항 위에서 설명한 솔루션에 대한 몇 가지 추가 고려 사항은 다음과 같습니다.
### 요청 범위가 아닌 흐름 테스트하기
제안된 솔루션은 외부 요청을 포함하지 않는 배치 작업과 같은 특정 유형의 플로우를 테스트하는 데 충분하지 않을 수 있습니다. 예를 들어, 배치 작업이 데이터베이스에서 행을 읽고, 처리하고, Kafka에 메시지를 게시하는 경우, Kafka 헤더를 통해 가져오고 전파되는 행에서 테넌트ID를 사용할 수 있어야 할 수 있습니다.
### 카프카 컨슈머 전반에 걸친 분산 캐시 일관성
성능을 최적화하려면 중앙 서비스에서 검색된 매핑 결과를 모든 Kafka 컨슈머에게 로컬로 캐싱하는 것이 좋습니다. 그러나 이 캐싱은 중앙 서비스에서 매핑이 업데이트되었을 수 있기 때문에 오래된 데이터가 발생할 가능성이 있습니다. 캐시를 적절히 관리하여 Kafka 컨슈머 간에 캐시 일관성을 보장하는 것이 중요합니다.
### Kafka 컨슈머 그룹의 수명 주기
고유한 컨슈머 그룹 이름으로 Kafka 컨슈머를 연결하려면 애플리케이션 코드에서 또는 Kafka CLI를 통해 설정하도록 선택할 수 있습니다. 테넌트를 삭제할 때 해당 컨슈머 그룹도 삭제해야 Kafka 브로커의 리소스를 확보할 수 있다는 것을 기억하세요. 카프카 컨슈머 그룹의 라이프사이클이 테넌트의 라이프사이클과 동기화되도록 하는 것이 중요합니다.
### 카프카 컨슈머 그룹 오프셋
특정 사용 사례에 따라 Kafka 컨슈머에 대한 오프셋을 설정하는 것을 고려해야 합니다. 일반적인 시나리오는 기준 컨슈머의 오프셋을 사용하여 최신 메시지를 처리하는 것입니다.
## 결론
여러 테넌트에서 Kafka와 같은 비동기 시스템을 사용하는 환경을 확장할 때는 고유한 문제가 발생할 수 있습니다. 이러한 문제를 해결하기 위한 몇 가지 접근 방식이 있으며, 각 접근 방식은 리소스 격리 및 비용 측면에서 고유한 장점과 장단점을 가지고 있습니다. 가장 비용 효율적인 방법 중 하나는 테넌트 간에 공통 기준 환경을 공유하는 것입니다. 이 접근 방식을 사용하면 운영 오버헤드를 최소화하면서 확장 가능하고 격리된 테스트를 수행할 수 있으며 오래된 환경 문제를 해결할 수 있습니다. OpenTelemetry를 활용하여 Kafka를 통해 헤더를 전파하고 메시지를 동적으로 라우팅함으로써 높은 수준의 격리 및 유연성을 갖춘 Kafka 환경을 효율적으로 확장할 수 있습니다. 이 접근 방식은 다른 메시지 큐로 쉽게 확장할 수 있어 비동기 애플리케이션을 위한 다용도 솔루션이라는 점도 주목할 가치가 있습니다.
더 자세히 알아보시려면 Signadot 설명서를 확인하시거나 커뮤니티 Slack 채널에서 토론을 이어가세요.